*필자는 엘리스 AI 트랙 8기를 수강중이다. 당일 배운 내용에 대한 포스팅이다.
<1> 자연어 처리
01 자연어 처리 Natural Language Processing, NLP
자연어 처리 : 컴퓨터를 통해 인간의 언어를 분석 및 처리하는 인공지능의 한 분야
ex) 문서 분류, 키워드 추출 (불필요한 단어 제거), 감정 분석
자연어처리 + 머신러닝 : 학습 가능한 데이터양의 증가 및 연산 처리 속도의 발전으로 자연어 처리 또한 더욱 복잡한 머신러닝 알고리즘 적용 가능
ex) 문서 요약, 기계 번역, chat bot
02 텍스트 전처리
모델링을 위한 데이터 탐색 및 전처리
데이터 탐색 : 최소 단위(단어의 개수, 단어별 빈도수)를 기준으로 데이터 통계치 / 변수별 특징 등 ..
데이터 전처리 : 최소 단위(특수 기호 제거, 단어 정규화)를 기준으로 이상치 제거, 정규화 등..
토큰화 Tokenization : 주어진 텍스트를 각 단어 기준으로 분리하는 것
텍스트 1 : Hello my name is Elice! What is your name?
⇒ 소문자 처리 및 특수 기호 제거를 통해 동일한 의미의 토큰은 동일한 형태로 변환
-> hello my name is elice what is your name
counter = dict()
with open(파일명, 'r') as f:
for line in f:
for word in line.rstrip().split(): #한 줄 마다 줄바꿈 문자 제거, 공백 기준으로 나눔
if word not in word_counter: #빈도수 저장
word_counter[word] = 1
else:
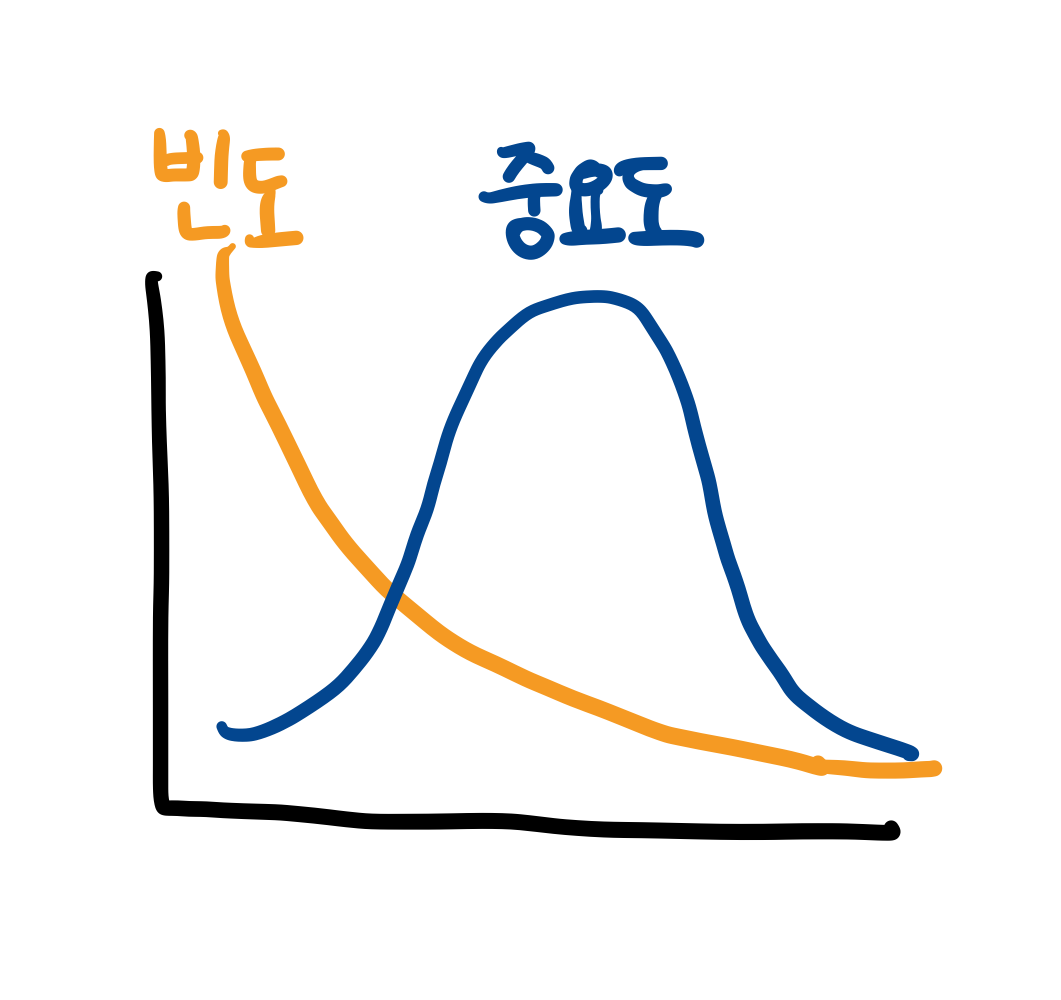
word_counter[word] += 1대부분 단어 빈도수의 분포는 지프의 법칙, Zipf’s law를 따름
전처리1. 특수 기호 제거
import re #re: 정규 표현식 라이브러리
word = "123hellow993 3939^"
regex = re.compile('[^a-z A-Z]') #a-z, 공백, A-Z만 잡아낼 것
print(regex.sub('', word)) #regex로 정의하지 않은 것들은 사라질 것 (공백으로)
전처리2. Stopword 제거 - 문법적인 기능을 지닌 단어 및 불필요하게 자주 발생하는 단어를 제거 (일종의 노이즈 제거)
import nltk #nature language took kit
from nltk.corpus import stopwords
setence = ["the","green","egg","and","a"]
stopwords = stopwords.words('english') #리스트를 반환
new_sentence = [word for word in sentence if word not in stopwords]
#stopwords에 없는 word만 new_sentence에 추가
new_stopwords = ["none"] #신규 stopwords 추가
stopwords = stopwords.words('English')
stopwords += new_stopwords전처리2. Stemming - 동일한 의미의 단어이지만, 문법적인 이유 등 표현 방식이 다양한 단어를 공통된 형태로 변환
import nltk
from nltk.stem import PorterStemmer
words = ["studies", "studied", "studying", "dogs","dog"]
stemmer = PorterStemmer() #객체
for word in words:
print(stemmer.stem(word)) #각 문자의 원형 반환03 단어 임베딩
컴퓨터는 텍스트를 포함하여 모든 데이터를 0과 1로 처리
자연어의 기본 단위인 단어를 수치형 데이터를 표현하는 것이 중요
단어 임베딩이란, 각 단어를 연속형 벡터로 표현하는 것.
비슷한 문맥에서 발생하는 단어는 유사한 의미를 가짐
ex) 서울에 살고 있는 엘리스는 강아지를 좋아한다
ex2) 뉴욕에 살고 있는 찰리는 고양이를 좋아한다
서울 - 뉴욕

즉 유사한 단어의 임베딩 벡터는 인접한 공간에 위치
임베딩 벡터 간 합과 차로 단어의 의미적 특징을 활용 가능
04 word2vec (단어 임베딩 학습) “문맥”
주어진 문맥에서 발생하는 단어를 예측하는 문제를 통해 단어 임베딩 벡터를 학습
서울에 살고 있는 ____는 강아지를 좋아한다.
각 단어의 벡터는 해당 단어가 입력으로 주어졌을 때 계산되는 은닉층의 값을 사용
from gensim.models import Word2Vec
doc = [["서울에", "살고", "있는","엘리스는","강아지를","좋아한다"]]
#토큰화된 문장
w2v_model = Word2Vec(min_count=1, window=2, vector_size=300)
#min_count보다 작게 언급되는 단어는 학습하지 않는다 => 다 학습함
#window는 문맥의 범위. 살고 있는 , 강아지를 좋아한다 => 입력값
#vector_size는 차원의 개수, 은닉층
w2v_model.build_vocab(doc) #수치형 인덱스 부여
w2v_model.train(doc, total_examples=w2v_model.corpus_count, epochs=20)
#corpus_count : 문서의 개수, epochs : 모든 데이터를 20번씩 순환
similar_word = w2v_model.wv.most_similar("엘리스는")
#임베딩 벡터 기준으로 가장 가까운 단어들을 출력
print(similar_word)
score = w2v_model.wv.similarity("엘리스는","좋아한다")
print(score) #점수 차
05 fastText (단어 임베딩 학습2)
word2vec는 존재하지 않았던 단어 벡터는 생성할 수 없음 (미등록 단어 문제, out-of-vocabulary)
⇒ 각 단어를 문자 단위로 나누어서 단어 임베딩 벡터를 학습
강아지 → 강, 강아, 강아지
⇒ 학습 데이이터에 존재하지 않았던 단어의 임베딩 벡터 또한 생성 가능
from gensim.models import FastText
doc = [["서울에" ~]]
ft_model = FastText(min_count=1, window=2, vector_size=300)
ft_model.build_vocab(doc)
ft_model.train(doc, total_examples=ft_model.corpus_count, epochs=20)
similar_word = ft_model.wv.most_similar("엘리스는")
new_vector = ft_model.wv["좋아한다고"] #신규 단어
print(new_vector)
<2> 자연어 처리 모델
01 순차 데이터란 ?
RNN(Recurrent Neural Network)은 CNN과 함께 대표적인 딥러닝 모델
시계열 데이터 같은 순차 데이터 처리를 위한 모델
-순차 데이터 : 순서를 가지고 있는 데이터
날짜에 따른 기온 데이터나 단어들로 이루어진 문장 등으로 유명, 데이터 내 각 개체간의 순서가 중요
-시계열 데이터 Time-Series Data : 일정한 시간 간격을 가지고 얻어낸 데이터
-자연어 데이터 Natural Language : 인류가 말하는 언어를 의미, 주로 문장 내에서 단어가 등장하는 순서에 주목
02 딥러닝을 활용한 순차 데이터 처리 예시
- 경향성 파악 (주가 예측, 기온 예측, 이외에도 다양한 시계열 특징을 가지는 데이터에 적용 가능)
- 음악 장르 분석 : 오디오 파일은 시계열 데이터, 음파 형태 등을 분석하여 오디오 파일의 장르를 분석
- 강수량 예측 : 구글에서 이미지 처리 기술과 결합하여 주도적으로 연구 (MetNet)
- 음성 인식 : 음성에 포함된 단어나 소리를 추출
- 번역기 : 두 언어간 문장 번역을 수행, 딥러닝의 발전 이후 번역의 자연스러움이 향상, 이미지 처리와 결합하여 실시간 번역도 제공
- 챗봇 : 사용자의 질문을 분석 후 질문에 적절한 응답을 생성
03 Recurrent Neural Network
Fully-connected Layer와 순차 데이터
Fc layer은 입력 노드 개수와 출력 노드 개수가 정해짐
순차 데이터는 하나의 데이터를 이루는 개체 수가 다를 수 있음
순서 고려가 불가능
⇒ 순차 데이터 처리를 위한 딥러닝 모델이 등장
Hidden State
x1, x2 , … 벡터 형태
각 데이터를 이루는 Feature 값들을 원소로 하여 벡터로 변환
[938.3 139 -1 … ]
자연어 데이터의 벡터 변환
임베딩 : 각 단어들을 숫자로 이루어진 벡터로 변환
One-hot Encoding: [1 0 0 0], [0 1 0 0] - 0과 1로만 이루어져 있으며 1은 항상 하나만 등장
Word2Vec: 주어진 단어들을 벡터로 변환하는 기계 학습 모델
04 Vanilla RNN : 가장 간단한 형태의 RNN 모델
내부에 세 개의 FC Layer 로 구성
- 현재 입력 값에 대한 새로운 hidden state 계산
- h_t = tanh(h_t-1 * W_hh + x_t * W_xh)
- tanh는 tangent hyperbolic 함수
선형 → 활성화 함수 추가(tanh) → 비선형성
모델에 들어오는 각 시점의 데이터마다 연산 과정을 수행
입력 값에 따라 반복해서 출력값과 hidden state를 계산
이전 시점에 생성된 hidden state를 다음 시점에 사용!
Vanilla RNN 의의
Hidden state: 입력값들의 상관관계나 경향성 정보를 압축해서 저장, 모델이 내부적으로 계속 가지는 값이므로 일종의 메모리, 컴퓨터의 메모리와 일맥 상통
Parameter Sharing: 모든 시점의 입력값이 재사용, FC layer세 개가 모델 파라미터의 전부
구조
입력값과 출력값의 구성에 따라 여러 종류의 RNN이 존재
-다대일 구조 (many-to-one)
-다대다 구조(mnay-to-many)
종류
인코더-디코더(Encoder-Decoder): encoder에서 생성된 hidden sate를 decoder로 전달
문제점
- RNN은 출력값이 시간 순서에 따라 생성
- 각 시점의 출력 값과 실제 값을 비교하여 손실(Loss)값을 계산
- 역전파 알고리즘이 시간에 따라 작용 → Back-propagation Through Time (BPTT)
- 입력값의 길이가 매우 길어질 경우(기울기 값이 점점 작아질 수도)
- ⇒ 기울기 소실 Vanishing Gradient 문제 발생! = 장기 의존성을 다루기가 어려움
<One-hot 인코딩 실습>
import tensorflow as tf
from tensorflow.python.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
#tokenizer : 파이선에서 제공하는 텍스트 데이터 전처리 모듈
#문자열로 구성된 데이터를 다양한 형태로 토큰화 가능
def set_token(texts): #문자열을 입력받아 tokenizer 반환
tokenizer=Tokenizer()
tokenizer.fit_on_texts(texts)
return tokenizer
def text2seq(text, tokenizer):#문자열을 시퀀스 정보로 변환
return tokenizer.texts_to_sequences([text])[0]
def seq2onehot(seq, num_word): #one-hot인코딩
return to_categorical(seq,num_classes=num_word+1) # 예약된 토큰을 위해 1자리를 추가로 사용
text1= "stand on the shoulders of giants"
text2= "I can stand on mountains"
tokenizer = set_token([text1, text2])
print("단어 수: ", len(tokenizer.word_index)) #9
print("단어 인덱스: ", tokenizer.word_index) # {'stand':1, ...}
seq = text2seq(text2, tokenizer)
print(seq) #[7, 8, 1, 2, 9]
onehot1 = seq2onehot(seq, len(tokenizer.word_index))
print(onehot1)
#단어 9가지를 나타내기 위한 9자리 + 모델에 입력하기 위해 1자리 = 총 10자리
#좀 더 긴 문장이라면 ?
text3 = "i have copy of this on vhs i think they the television networks should play this every year for the next twenty years so that we don't forget what was and that we remember not to do the same mistakes again like putting some people in the"
text4 = "he old neighborhood in serving time for an all to nice crime of necessity of course john heads back onto the old street and is greeted by kids dogs old ladies and his peer"
tokenizer2 = set_token([text1, text2, text3, text4])
print("단어 수: ", len(tokenizer2.word_index)) #69
print("단어 인덱스: ", tokenizer2.word_index)
seq2 = text2seq(text2, tokenizer2)
onehot2 = seq2onehot(seq2, len(tokenizer2.word_index))
#길게 표현 됨
#I 한글자를 위해 70차원의 벡터가 필요함. 비효율적'Heute lerne ich > AI' 카테고리의 다른 글
| [엘리스] 문서 유사도 및 언어 모델 (0) | 2023.09.28 |
|---|---|
| [엘리스] 자연어 처리 및 문장 유사도 / 모델 심화 (1) | 2023.09.28 |
| [엘리스] 모델 학습 및 서비스 (0) | 2023.09.28 |


